
おつかれさまです。すぺきよです。
最近仕事でS3 + Glue + Athenaでデータ分析用のテーブルを作成しようと調査をしています。
S3にはcsvファイルを設置、Glueのクローラーでテーブル定義を自動作成してもらって、Athenaでどのようなデータが出来上がるのかいろいろと試していました。
CSVからGlueのテーブルを作成し、Athenaのクエリでデータ参照できることは確認できました。
その時、ふとデータ内にカンマやダブルクオーテーションが入っていたら・・・?
流石にAWSさんだからその辺は上手くやってくれているとたかをくくっていたのですが、なんとデフォルトの設定ではうまく取り込めません。
色々調べた結果、うまく取り込むための設定が見つかったので備忘録として置いておきます。
CSVファイルのエスケープについて
CSV(カンマ区切り値)ファイルでは、データ内に特定の文字(カンマ、改行、ダブルクォートなど)が含まれる場合、正しく解析できるようにエスケープ処理が必要になります。
CSVファイルとは以下のように各データが間まで区切られたデータです。
123456,Apple,Tokyoカンマで区切られているので、データ内にカンマが含まれていた場合は、思い通りのデータの区切りになりません。(以下は2つ目のセルに「app,le」が含まれていた場合)
123456,App,le,Tokyoそういう時はエスケープ処理を施して、以下のようにダブルクォートで囲うというエスケープ処理を行います。
123456,"App,le",Tokyoさらに、データ内にダブルクォートが含まれる場合は、ダブルクォートで囲ったとしてもデータの区切りがおかしくなります。
こういう時は以下のように、ダブルクォートを2重化する方法を取るのが一般的です(以下は2つ目のセルに「app”le」が含まれえていた場合)
123456,"App""le",TokyoCSVを扱っていると、データ内にカンマやダブルクォートが含まれることはまれに良くあります。
しかし、Glueのデフォルト設定ではこのエスケープ済みのCSVの読み取りに対応していません。
結局何がしたいのか
次のような各種エスケープがされているCSVファイルがあったとして、
キー,値
key1,value1
key2,"value2"
key3,"val,ue3"
key4,"val""ue4"
key5,"va,l""u,e5"初期設定のままだと、Athenaのクエリの結果表示は以下になってしまいます。
key3に対する値が途中で欠けていますし、エスケープ用のダブルクォートもそのまま残っています。
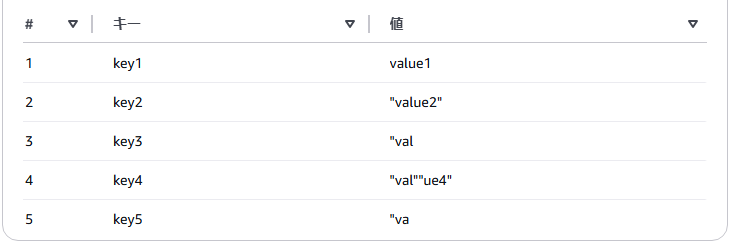
これを、Glueの設定を変更することで、以下のクエリ結果のようにしたいわけです。
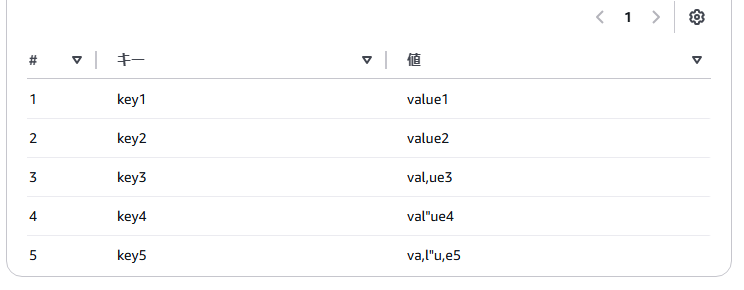
どう対応すればよいか
では、実際の対応手順です。
Glue上の左ペインのTableから対象のテーブルを一覧を開き、問題を起こしているテーブルを開きます。
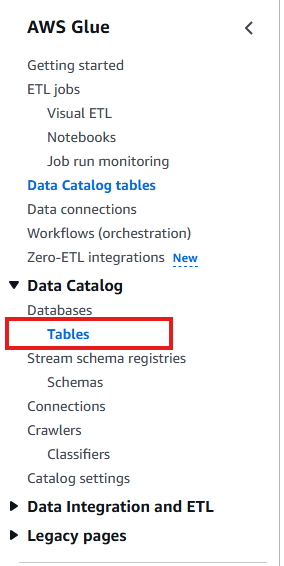
画面右上の「Action」から「Edit Table」を選択します。
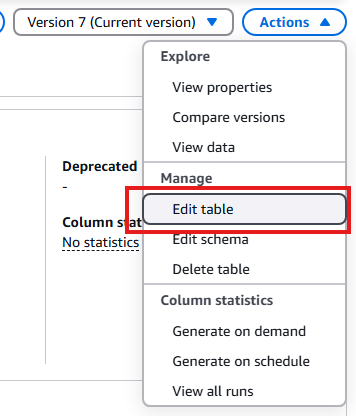
注目するポイントは「Serialization lib」と「Serde parameters」の値です。
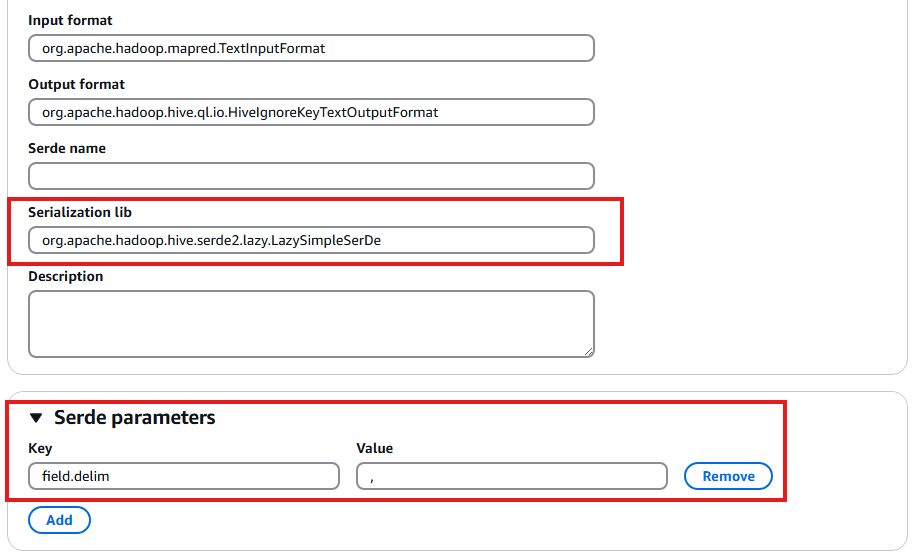
ここはおそらくデフォルトでは以下のような設定になっているはずです。
Table Details
| Parameter Name | Value |
|---|---|
| Serialization lib | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
Serde parameters
| Key | Value |
|---|---|
| field.delim | , |
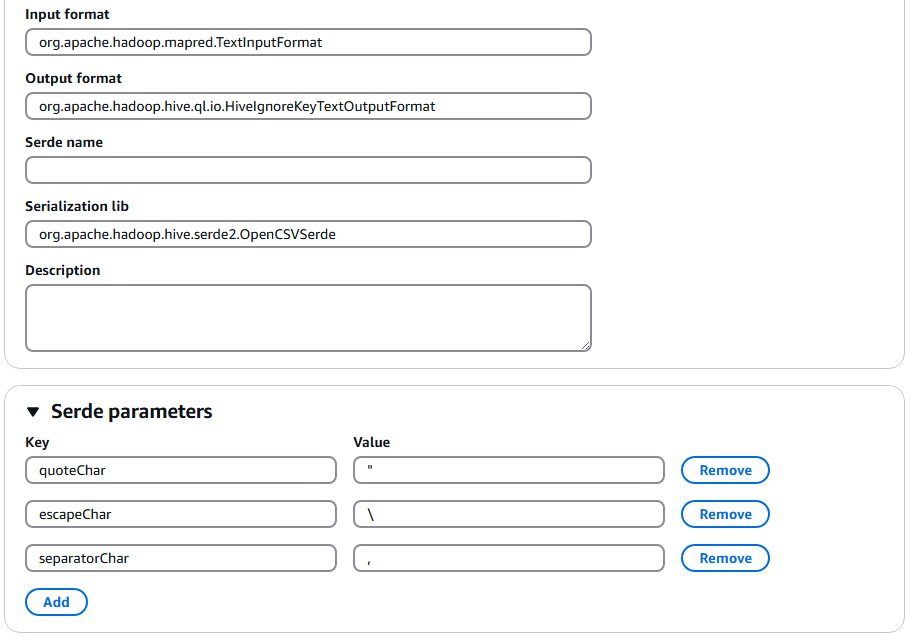
ここを以下のように変更します。
Table Details
| Parameter Name | Value |
|---|---|
| Serialization lib | org.apache.hadoop.hive.serde2.OpenCSVSerde |
Serde parameters
| Key | Value |
|---|---|
| quoteChar | “ |
| escapeChar | ¥ |
| separatorChar | , |
変更後は以下のイメージのような設定になります。
この設定を保存したら、Athena上の表示がきれいになっているはずです。
からくりは?
GlueとAthenaは内部的にHadoopを使っているようです。
テーブル作成時に指定できるSQLは少し特殊で一般的なRDBMSのSQLとは違い、CREATE TABLEの定義は以下のようになっています。
CREATE EXTERNAL TABLE [IF NOT EXISTS]
[db_name.]table_name [(col_name data_type [COMMENT col_comment] [, ...] )]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[WITH SERDEPROPERTIES (...)]
[LOCATION 's3://amzn-s3-demo-bucket/[folder]/']
[TBLPROPERTIES ( ['has_encrypted_data'='true | false',] ['classification'='aws_glue_classification',] property_name=property_value [, ...] ) ]引用元 : https://docs.aws.amazon.com/ja_jp/athena/latest/ug/create-table.html
今回問題となっている設定は、この定義の中の[ROW FORMAT row_format]の部分の設定内容です。
ここがデフォルトでは以下の記述になっており、このままでは「単純にカンマでしか区切らない」という指定となってしまっています。
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',' この設定を以下の記述に変更すれば解決します。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"',
'escapeChar' = '\\'
)引用元 : https://docs.aws.amazon.com/ja_jp/athena/latest/ug/csv-serde.html
先に記載したGlueの画面上での手順は、個々の設定をUIから書き換えています。
Athenaで変更するには
Alterコマンドなどで定義を変更できないか調べてみましたが、どうやら変更する方法がないっぽい・・・?
なのでAthenaからテーブル定義を変更しようとすると、クエリエディタ上で以下の手順を踏む必要があるのではないかと思います。
- 対象のテーブルのDDLを取り出す
- DDLのROW FORMATの定義を「org.apache.hadoop.hive.serde2.OpenCSVSerde」を使った定義に書き換える
- 既存のテーブルをドロップ
- ROW FORMATの定義を書き換えたDDLでテーブルを作り直す
こちらの方法は機械的に大量にテーブル定義を行う場合に使えそうですね。
セル内に改行が含まれたCSVはどうしたの!?
CSVのエスケープの一般的な仕様には、改行をセル内に含むことができます。
セルをダブルクオーテーションで囲ってしまえば、データ内に改行を入れたとしても、1つのセルとして認識することが一般的です。
例えば以下のようなセルですね。
"value1
value2
value3"しかし「org.apache.hadoop.hive.serde2.OpenCSVSerde」はこれに対応していないそうで、このようなセルを読み取ろうとしたらnull扱いになってしまいます。
CSV を処理するための Open CSV SerDe:の「文字列データに関する考慮事項」のブロックにも下記通り明記されています。
Open CSV SerDe は、CSV ファイルの埋め込み改行をサポートしません。なので、この動作が正常なのではないかと思われます。
色々調べたのですが、これだけはどうにもならなさそうでした・・・。
どうしても改行を含めたいのであれば、Base64やURLエンコードなどでエンコードし、画面に表示する前にデコードするしか、現状はなさそうです。
そもそもデータ分析用のCSVファイルに改行が含まれるセルが出てくるのか?という問題はありそうですが。
まとめ
今回はS3 + Glue + Athenaの構造のエスケープ済みのCSVファイルを扱う方法についてまとめました。
CSVファイルを扱えるようにしているのだから、このあたりデフォルトでちゃんと読めるようにしといてよと個人的には思います。
もしかするとCSVを取り込む際にDPUを消費し、この辺りのエスケープを考慮した処理をしてしまうとコストが上がってしまうのかもしれません。
そのため一番コストのかからないものがデフォルトになっているのかなとも思ったりします。
この記事が、誰かのAthenaにCSVを読ませる方法の手助けになれば幸いです
ここまでお付き合いありがとうございました。

